Artificial Intelligence for Image Production: Artistic Perspectives
Over the last 7 years we have been witnessing the development of Artificial Neural Networks for image production: from Google Deep Dream and StyleTransfer algorithms to GANs (Generative Adversarial Networks) and CLIP (Contrastive Language-Image Pre-Training) architecture for text-to-image generation.
While these instruments are becoming more accessible, many artists start using them in their practices. However, artistic approaches differ from what we see in design or computer science research. While scientists consider the results they get through the Neural Network training from the perspective of optimisation or utility, artists are looking for specific agency and the aesthetics of technology through its creative misuse, poetic abuse and hack.
We will study artistic twists and hacks of these instruments “demystifying new technologies while highlighting some socio-political issues … and exploring the limitations of art as a debunker of techno-hype” (Joanna Zilinska). In this case study I’m writing about my own projects and works of my students, created during the course “Art & Science practical course N1: Artificial Intelligence as an artistic phenomenon” at Rodchenko Art School during spring semester in 2021. To understand the way artists deviate from the norm established by tech companies we have to learn what this norm is and how these technologies are meant to be used.
I. Dataset
Dataset is an array of data used to train a neural network. Datasets used in computer science and industry are usually consistent and the variety of the images in dataset is low.
In my projects The Other View (2018) I connected to IP-cameras at a mirror gallery imitating Yayoi Kusama’s mirror installations. The visitors are taking “selfies” in these mirrors and posting them on social media. This project demonstrated the supplementation of IP-camera surveillance by data we provide ourselves through self-representation on social media.

An IP-camera at the mirror gallery is installed to look down from above the entrance and shows a non-human point of view by observing reality as it is. At the same time, visitors represent clichés of social constructs by looking at themselves from an “imaginary Other’s” point of view.
In this work, I’m exploring two perspectives of surveillance: first, the gathering of our data by tech companies through social-media based on the information we provide in exchange for their free services and, second, the surveillance of our physical presence by IoT devices, in this case IP-cameras.
For The Other View v. 2 (2020) I used the data collected from social media in the previous part of the project as a dataset. AI generalised the features it extracted from the dataset and emphasised the characteristics which were more common for construction of the image in a context of selfie-culture: the postures, the filters, the composition of the photo representing social constructs through the lens of social media.


In “Neurofrodite” video by Nika Peshekhonova, the artist creates video and visualisations using 3D models rendered from images of people generated by the StyleGan2 neural network. “The neural network was trained on a dataset of three hundred photographs of naked people of various sizes and ages, who are workers in the porn industry” (Nika Peshekhonova) From images generated by AI the artist selected glitched and distorted images looked like pictures of transgendered bodies. These pictures represent not the dataset itself, but the artistic concept: the fluid future of gender.

II. Fine-tuning
Since Machine Learning is very resource intensive process, we don’t have to train AI from scratch every time, but we can take some pre-trained model and fine-tune it using our own considerably small dataset. There is a transition moment while the model is learning features from the dataset. In the following image you can see the example of this phenomena: during the workshop my student Emma Bayer used a model trained on images of cats and was fine-tuning it on dataset of images of brain computer-tomography. The model is already learned how computer tomography looks like, but it still represents the features of cats.
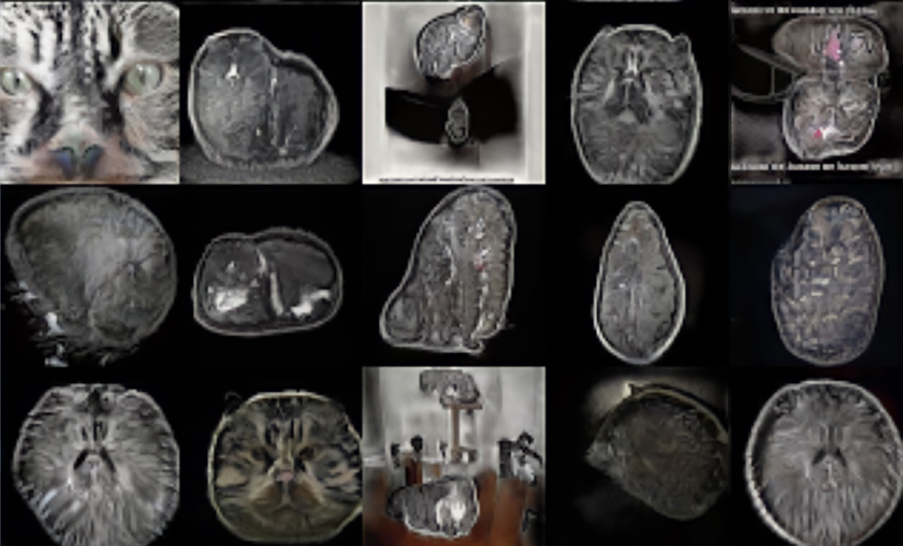
For “Stopping Light” video Ivan Netkachev used the StyleGAN2 neural network, trained on images of churches. He retrained it on a dataset of virtual in-game photography from GTA San Andreas. The architecture from video game is merged with real architectural forms. The artist stopped the process of training of AI on a very early stage: “churches freeze between reality and rough polygonal space” (Ivan Netkachev). From computer science perspective the model was poorly trained, but through the misuse of technology the artist finds the peculiar visual aesthetics.

III. Latent Space
Latent Space represents what AI learned from data it was trained on. All videos possessing morphing AI aesthetics we usually see are basically the interpolations in latent space. This space is hidden by default and introduces the problem of “Black box” of AI: it often contains biases learned from the datasets created by human engineers. The “Manifesting Latent Space” project by Roman Solodkov “invites participants to explore the latent space by playing with it, in order to make it visible and tangible, accessible for interaction to a human user. It simultaneously poses a question: who can play with the structure of powerful commercial / corporate neural networks, and who is affected by the consequences of these games?” (Roman Solodkov). The artist created physical interface to interact with the latent space of AI: by moving the red ball, visitors of the show made neural network to travel through the latent space. The result of the interaction is the live-video of AI interpolations.

IV. Text-to-image generators
CLIP transformer is the approach to text-to-image AI presented by OpenAI, but then implemented and trained by many researchers and AI-enthusiasts. This transformer architecture merges two generative models: GPT-2 or -3 which possessso called attention mechanism based on vectors and is capable to analyse the context of the text and an adversarial network usually trained on a huge dataset of labeled images previously created for computer vision systems. “Despite the common mythos that AI and the data it draws on are objectively and scientifically classifying the world, everywhere there is politics, ideology, prejudices, and all of the subjective stuff of history” (Trevor Paglen and Kate Crawford). Tech companies and computer scientists developing these algorithms operate in terms of quality, stability, efficiency. They usually want AI-generated image to look as photorealistic as possible and visually appealing.
“You can touch, you can play” project by Anna Shustikova explores “the biases around concepts of “beauty” and “femininity” within machine’s male gaze, using much-talked-about CLIP (text-to-image) AI architecture” (Anna Shustikova). Anna worked with AI trained on ImageNet database – one of the most popular datasets in the world, widely used by computer scientists and engineers in research as well as in IT-industry. One of the first stages of the project the artist experimented with CLIP architecture, generating images with the text prompts such as “woman” and “beautiful”. The representation of this stage were the 3d printed sculptures.


Another stage of the project was shown at the “Uncanny Dream” exhibition as part of Ars Electronica Festival 2021 (curated by Helena Nikonole and Oxana Chvyakina). During the exhibition Anna invited the visitors to create their own database for AI: a “proper”, more diverse dataset representing concepts of beauty and femininity. The results were later presented on the exhibition website.

1. Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, (https://arxiv.org/abs/1406.2661, 2014)
2. Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen, Hierarchical Text-Conditional Image Generation with CLIP Latents (https://arxiv.org/abs/2204.06125, 2022)
3. Joanna Zilinska, Nonhuman Photography (MIT Press, 2017)
4. Joanna Zilinska, AI Art: Machine Visions and Warped Dreams (MIT Press, 2020)
5. Vladan Joler, Matteo Pasquinelli, Nooskope.AI (2020)
6. Kate Crawford and Trevor Paglen, “Excavating AI: The Politics of Training Sets for Machine Learning (September 19, 2019) https://excavating.ai
Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.